2.5.5
Gaussian Mixture
สรุป
- GMM มองข้อมูลเป็นผลรวมของการแจกแจงปกติหลายตัว จึงเป็นโมเดลกำเนิดที่บรรยายข้อมูลทั้งชุดด้วยความน่าจะเป็น
- สามารถคืน “หน้าที่รับผิดชอบ” (responsibility) หรือความน่าจะเป็นที่จุดหนึ่งมาจากคลัสเตอร์ใด ช่วยสื่อความไม่แน่นอนได้
- ปรับพารามิเตอร์ด้วยอัลกอริทึม EM และเลือกโครงสร้างโคเวเรียนซ์ (
full,tied,diag,spherical) ให้เหมาะ - ใช้เกณฑ์ BIC/AIC เพื่อเลือกจำนวนองค์ประกอบและสุ่มเริ่มต้นหลายครั้งเพื่อหลีกเลี่ยงจุดติด
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
ความน่าจะเป็นของเวกเตอร์ \(\mathbf{x}\) คือ
$$ p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \, \mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k), $$โดย \(\pi_k\) เป็นค่าน้ำหนัก (รวมเป็น 1), \(\boldsymbol{\mu}_k\) ค่าเฉลี่ย และ \(\boldsymbol{\Sigma}_k\) เมทริกซ์โคเวเรียนซ์ EM algorithm ทำสองขั้นตอนสลับกัน:
- E-step: คำนวณความรับผิดชอบ $$ \gamma_{ik} = \frac{\pi_k \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^K \pi_j \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)}. $$
- M-step: ใช้ \(\gamma_{ik}\) ปรับ \(\pi_k, \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k\)
ทดลองด้วย Python #
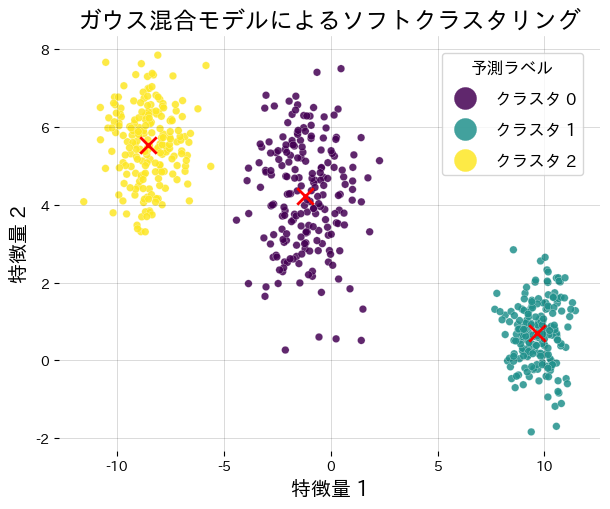
ตัวอย่างต่อไปนี้เรียนรู้ GMM 3 คลัสเตอร์และวาดศูนย์กลางพร้อมรายงานความรับผิดชอบ
| |
เอกสารอ้างอิง #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, Series B.
- scikit-learn developers. (2024). Gaussian Mixture Models. https://scikit-learn.org/stable/modules/mixture.html