2.5.3
X-means
สรุป
- X-means เป็นส่วนขยายของ K-means ที่ประเมินการแยกคลัสเตอร์ด้วยเกณฑ์ BIC/MDL เพื่อประมาณจำนวนคลัสเตอร์อัตโนมัติ.
- การกำหนดจำนวนคลัสเตอร์ขั้นต่ำและสูงสุดช่วยจำกัดช่วงค้นหาและลดปัญหาแบ่งคลัสเตอร์มากเกินไป.
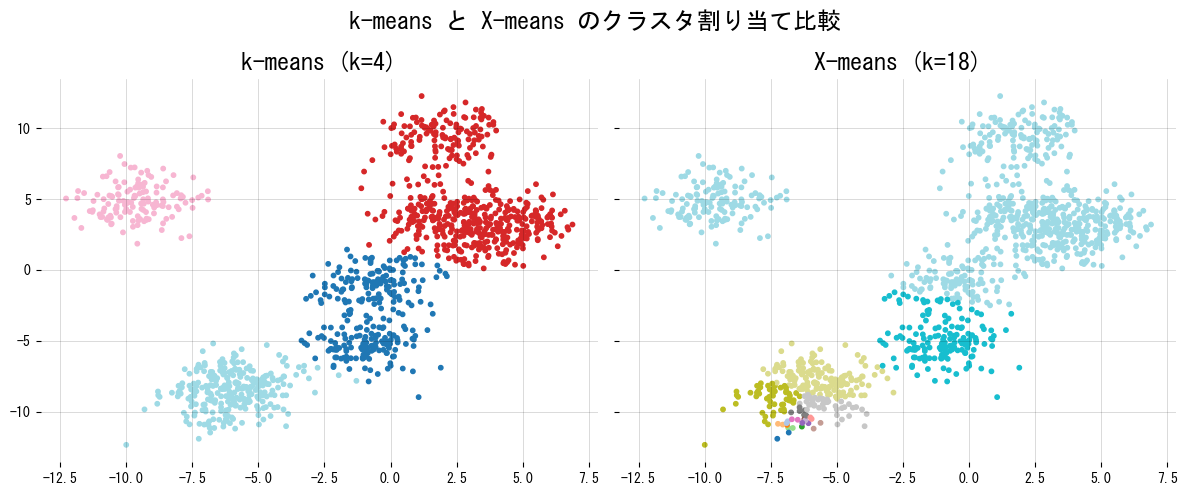
- การเปรียบเทียบกับ K-means แบบกำหนด k คงที่ช่วยเห็นผลของการเลือกจำนวนคลัสเตอร์ต่อการตีความข้อมูล.
สัญชาตญาณ #
X-means ใช้แนวคิดแบ่งแล้วทดสอบ เริ่มจากคลัสเตอร์หยาบก่อน แล้วจะแบ่งเพิ่มเฉพาะกรณีที่เกณฑ์สถิติชี้ว่าดีขึ้น วิธีนี้ลดการเดา k ด้วยมือและยังควบคุมความซับซ้อนได้ดี.
คำอธิบายโดยละเอียด #
X-means | ประมาณจำนวนคลัสเตอร์อัตโนมัติ #
สรุป
- X-means ขยาย k-means ให้เลือกจำนวนคลัสเตอร์เองโดยลองแบ่งคลัสเตอร์ย่อยตามความจำเป็น
- เมื่อแบ่งคลัสเตอร์หนึ่งเป็นสอง จะคำนวณเกณฑ์ BIC/MDL หากค่าดีขึ้นจึงยอมรับการแบ่ง
- สามารถเขียนเวอร์ชันง่ายๆ ได้ด้วยการรัน k-means และคำนวณ BIC ด้วยตัวเอง ไม่จำเป็นต้องมีไลบรารีเฉพาะ
- เหมาะกับสถานการณ์ที่กำหนด \(k\) ล่วงหน้าได้ยาก เพราะปล่อยให้ข้อมูลชี้นำจำนวนกลุ่มที่เหมาะสม
ภาพรวมเชิงสัญชาติญาณ #
k-means ต้องระบุ \(k\) ล่วงหน้า X-means แก้ด้วยการเริ่มจาก \(k\) เล็กๆ แล้วตรวจทุกคลัสเตอร์ว่าสมควรแบ่งต่อหรือไม่: ถ้าแบ่งแล้ว BIC ดีขึ้นก็เก็บทั้งสองคลัสเตอร์ใหม่ไว้พิจารณาต่อ เมื่อไม่มีคลัสเตอร์ไหนควรแบ่ง ตัวเลข \(k\) ก็ถูกกำหนดอัตโนมัติ
สูตรสำคัญ #
ให้คลัสเตอร์ \({C_1,\ldots,C_k}\) กับศูนย์กลาง \({\mu_j}\) BIC สำหรับโมเดลหนึ่งคำนวณได้จาก
$$ \mathrm{BIC} = \ln L - \tfrac{p}{2} \ln n, $$โดย \(L\) คือ likelihood, \(p\) จำนวนพารามิเตอร์ และ \(n\) จำนวนตัวอย่าง ถ้า BIC หลังแบ่งใหญ่กว่าแสดงว่าโมเดลใหม่ดีกว่า เราจึงยอมรับการแบ่งนั้น
ทดลองด้วย Python #
โค้ดต่อไปนี้สร้างเวอร์ชันอย่างง่ายของ X-means และเปรียบเทียบกับ k-means ที่ตั้ง \(k=4\) คงที่
| |
เอกสารอ้างอิง #
- Pelleg, D., & Moore, A. W. (2000). X-means: Extending k-means with Efficient Estimation of the Number of Clusters. ICML.
- Bahmani, B., Moseley, B., Vattani, A., Kumar, R., & Vassilvitskii, S. (2012). Scalable k-means++. VLDB.
- scikit-learn developers. (2024). Clustering. https://scikit-learn.org/stable/modules/clustering.html