2.1.6
การถดถอยเชิงเส้นแบบเบย์
สรุป
- การถดถอยเชิงเส้นแบบเบย์มองค่าสัมประสิทธิ์เป็นตัวแปรสุ่ม จึงประมาณได้ทั้งค่าคาดหวังและความไม่แน่นอนของผลพยากรณ์พร้อมกัน
- สามารถหาส่วนกระจายภายหลังได้แบบปิดรูปจากข้อมูลและการแจกแจงล่วงหน้า ทำให้ทำงานได้ทนทานแม้ข้อมูลมีค่าผิดปกติหรือมีปริมาณน้อย
- การแจกแจงพยากรณ์เป็นแบบแกาสเซียน จึงแสดงค่าเฉลี่ยและช่วงความเชื่อมั่นเพื่อช่วยการตัดสินใจได้ง่าย
- ใน
scikit-learnใช้BayesianRidgeก็จะประมาณความแปรปรวนของสัญญาณและของสัญญาณรบกวนให้อัตโนมัติ เหมาะกับงานจริง
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
ให้เวกเตอร์สัมประสิทธิ์ \(\boldsymbol\beta\) มีการแจกแจงก่อนหน้าเป็นแกาสเซียนหลายมิติที่มีค่าเฉลี่ยศูนย์และความแปรปรวนร่วม \(\tau^{-1}\mathbf{I}\) และสมมติสัญญาณรบกวน \(\epsilon_i \sim \mathcal{N}(0, \alpha^{-1})\) จะได้การแจกแจงภายหลัง
$$ p(\boldsymbol\beta \mid \mathbf{X}, \mathbf{y}) = \mathcal{N}(\boldsymbol\beta \mid \boldsymbol\mu, \mathbf{\Sigma}) $$โดยมี
$$ \mathbf{\Sigma} = (\alpha \mathbf{X}^\top \mathbf{X} + \tau \mathbf{I})^{-1}, \qquad \boldsymbol\mu = \alpha \mathbf{\Sigma} \mathbf{X}^\top \mathbf{y} $$เมื่อได้เวกเตอร์ใหม่ \(\mathbf{x}*\) การแจกแจงของคำตอบก็ยังเป็นแกาสเซียน \(\mathcal{N}(\hat{y}, \sigma_^2)\) เช่นเดิม BayesianRidge ใน scikit-learn จะประมาณ \(\alpha\) และ \(\tau\) จากข้อมูลให้ด้วย จึงใช้งานกรอบนี้ได้สะดวก
ทดลองด้วย Python #
ตัวอย่างด้านล่างใช้ข้อมูลเส้นตรงที่มี noise และ outlier เพื่อเปรียบเทียบระหว่างการถดถอยเชิงเส้นแบบกำลังสองน้อยที่สุดกับการถดถอยแบบเบย์
| |
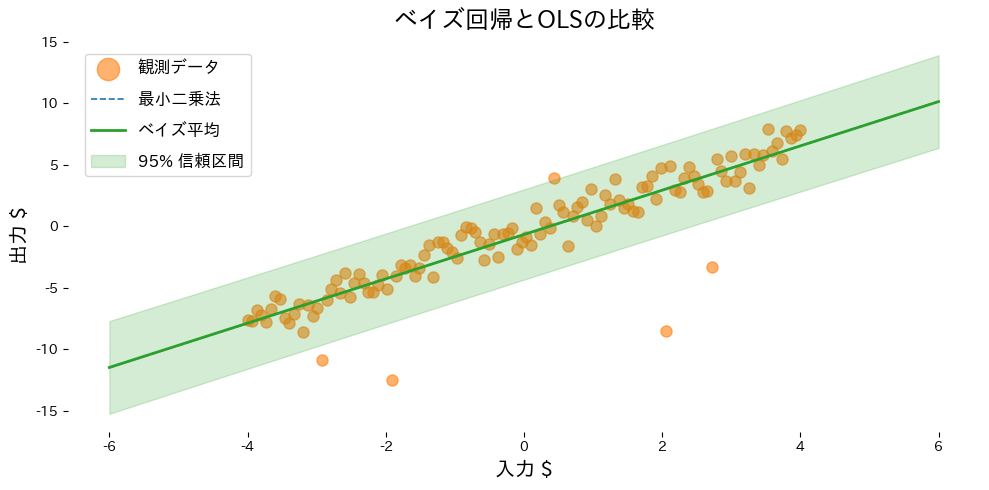
วิเคราะห์ผลลัพธ์ #
- OLS ถูกดึงให้เอียงตาม outlier ได้ง่าย ในขณะที่แบบเบย์สามารถหาค่าเฉลี่ยที่เสถียรกว่า
- เมื่อใช้
return_std=Trueจะได้ส่วนเบี่ยงเบนมาตรฐานของการพยากรณ์ จึงวาดช่วงความเชื่อมั่นได้ทันที - ตรวจสอบความแปรปรวนภายหลังของสัมประสิทธิ์เพื่อดูว่าคุณสมบัติใดยังมีความไม่แน่นอนอยู่มาก
เอกสารอ้างอิง #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.