2.1.11
Weighted Least Squares
สรุป
- WLS ให้ค่าน้ำหนักกับแต่ละการสังเกตตามความเชื่อถือ จึงประมาณเส้นถดถอยได้ดีแม้ noise ไม่เท่ากัน
- การคูณน้ำหนักกับกำลังสองของส่วนคลาดเคลื่อนทำให้จุดที่มีความแปรปรวนต่ำส่งผลมากกว่า และไม่ถูกลากด้วยจุดที่ noisy
LinearRegressionของscikit-learnรองรับ WLS เพียงระบุsample_weight- น้ำหนักอาจมาจากความรู้โดเมน การคาดประมาณความแปรปรวน หรือจากการวิเคราะห์ residual
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
ให้ค่าน้ำหนัก \(w_i > 0\) กับแต่ละการสังเกตแล้วทำให้
$$ L(\boldsymbol\beta, b) = \sum_{i=1}^{n} w_i \left(y_i - (\boldsymbol\beta^\top \mathbf{x}_i + b)\right)^2 $$ต่ำสุด หากทราบความแปรปรวน \(\sigma_i^2\) ของแต่ละจุดล่วงหน้า ค่าน้ำหนักที่เหมาะคือ \(w_i \propto 1/\sigma_i^2\)
ทดลองด้วย Python #
ตัวอย่างต่อไปนี้สร้างข้อมูลที่ครึ่งหนึ่งมี noise ต่ำ อีกครึ่ง noise สูง แล้วเปรียบเทียบ OLS กับ WLS
| |
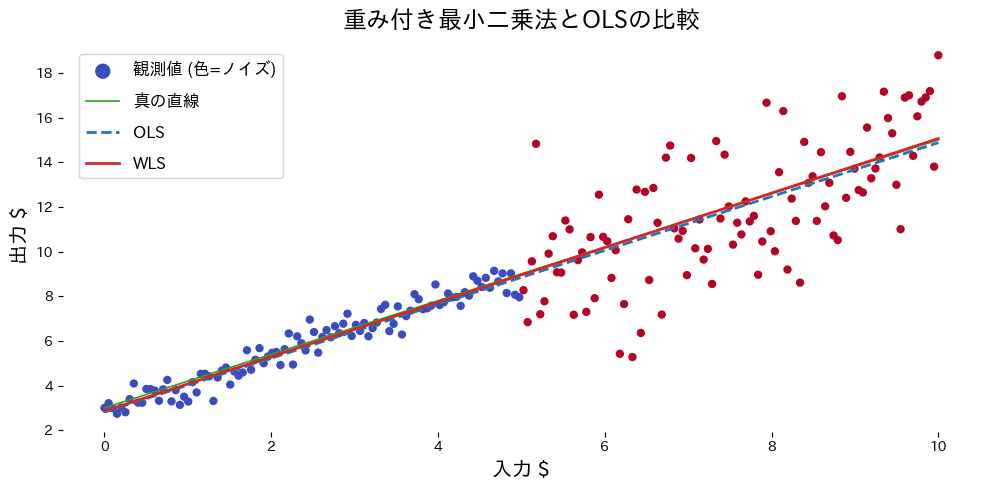
วิเคราะห์ผลลัพธ์ #
- เมื่อเติมน้ำหนักตามความแปรปรวน จุดที่ noise ต่ำมีอิทธิพลมากขึ้น เส้น WLS จึงเข้าใกล้เส้นจริงกว่า OLS
- OLS ถูกลากไปตามส่วนที่ noise สูง ผลคือความชันต่ำเกินจริง
- การออกแบบน้ำหนักอย่างเหมาะสมเป็นหัวใจของ WLS อาจใช้สูตรจากทฤษฎีหรือประเมินจาก residual ก็ได้
เอกสารอ้างอิง #
- Carroll, R. J., & Ruppert, D. (1988). Transformation and Weighting in Regression. Chapman & Hall.
- Seber, G. A. F., & Lee, A. J. (2012). Linear Regression Analysis (2nd ed.). Wiley.