2.3.2
Decision Tree (Regressor)
สรุป
- ต้นไม้สำหรับถดถอยแบ่งพื้นที่ฟีเจอร์เป็นช่วง ๆ แล้วทำนายด้วยค่าคงที่ในแต่ละใบ
- การแบ่งเลือกจากการลด MSE ระหว่างโหนดซ้ายและขวา
- พารามิเตอร์อย่าง
max_depth,min_samples_leaf, และccp_alphaช่วยบาลานซ์ความแม่นยำกับการอธิบาย - การวาดกราฟช่วยอธิบายว่าบริเวณใดได้ค่าทำนายเหมือนกัน
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
1. ภาพรวม #
เหมือนกับตัวจำแนก ต้นไม้ถดถอยถามคำถามง่าย ๆ จากฟีเจอร์ แต่เป้าหมายเป็นค่าต่อเนื่อง ใบไม้จะทำนายค่าคงที่ (ค่าเฉลี่ยของตัวอย่างที่ตกมาในใบนั้น) ยิ่งลึกยิ่งจับรายละเอียดได้มาก แต่เสี่ยง overfitting มากขึ้น
2. เกณฑ์การแบ่ง (ลดความแปรปรวน) #
ให้โหนด (t) มี (n_t) ตัวอย่าง และค่าเฉลี่ยเป้าหมาย (\bar{y}_t)
$$ \mathrm{MSE}(t) = \frac{1}{n_t} \sum_{i \in t} (y_i - \bar{y}_t)^2. $$เมื่อแบ่งด้วย (x_j) ที่ค่า (s) จะได้โหนดย่อย (t_L), (t_R) และคำนวณ
$$ \Delta = \mathrm{MSE}(t) - \frac{n_L}{n_t} \mathrm{MSE}(t_L) - \frac{n_R}{n_t} \mathrm{MSE}(t_R). $$เลือก split ที่ทำให้ (\Delta) มากที่สุด และหากไม่เพิ่มขึ้น โหนดจะกลายเป็นใบไม้
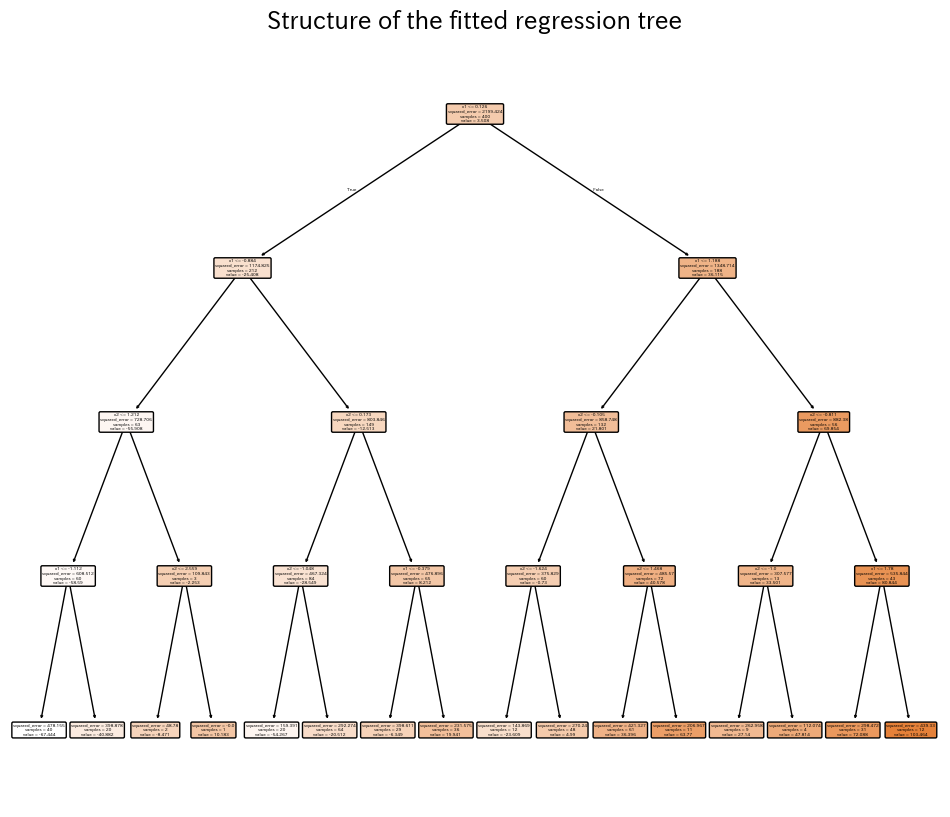
3. ตัวอย่าง Python #
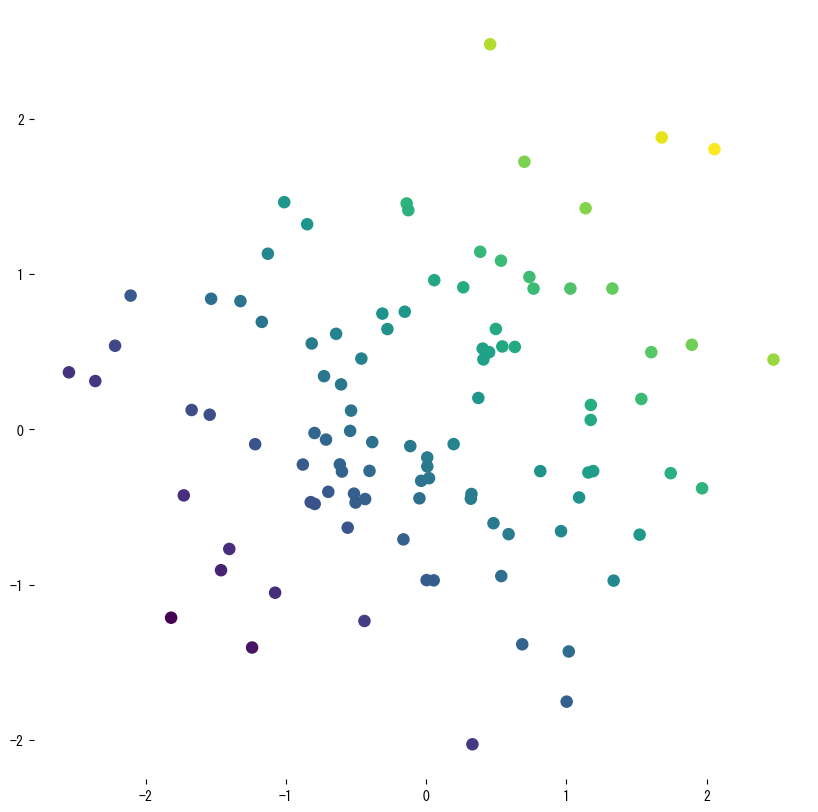
ตัวอย่างแรกสร้างข้อมูลจากเส้น sine แล้วฝึกต้นไม้ตื้น ๆ เพื่อให้เห็นการทำนายแบบขั้นบันได ตัวอย่างที่สองฝึกต้นไม้ด้วยฟีเจอร์ 2 ตัว แล้ววัด (R^2), RMSE, MAE พร้อมวาดพื้นผิวทำนาย
| |
| |
| |

4. อ้างอิง #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html