2.3.3
Decision Tree Parameters
- ต้นไม้ตัดสินใจมีพารามิเตอร์ที่ควบคุมความซับซ้อน เช่น ความลึก จำนวนตัวอย่างขั้นต่ำ และการ pruning
max_depthและmin_samples_leafจำกัดขนาดของกฎ ขณะที่ccp_alphaใช้ pruning แบบ cost-complexity- การเลือกเกณฑ์ (
squared_error,absolute_error,friedman_mse) ส่งผลต่อความไวต่อ outliers - การมองกราฟขอบเขตและโครงสร้างต้นไม้ช่วยอธิบายว่าพารามิเตอร์ที่เลือกเหมาะสมอย่างไร
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
1. ภาพรวม #
ต้นไม้จะขยายโดยเลือก split ที่ลดความไม่บริสุทธิ์ได้มากที่สุด หากไม่มีข้อจำกัด ต้นไม้มักโตจน overfit จึงต้องใช้พารามิเตอร์เป็นตัวควบคุม เช่น จำกัดความลึก กำหนดจำนวนตัวอย่างขั้นต่ำต่อใบ และทำ pruning เพื่อตัดกิ่งที่ไม่คุ้มค่า
2. Impurity gain และ cost-complexity pruning #
สำหรับโหนดพ่อ (P) ที่แบ่งเป็น (L) และ (R) การลด impurity คือ
$$ \Delta I = I(P) - \frac{|L|}{|P|} I(L) - \frac{|R|}{|P|} I(R), $$โดย (I(\cdot)) อาจเป็น Gini, entropy, MSE หรือ MAE ตามงาน หาก (\Delta I \le 0) จะไม่เก็บ split
Cost-complexity pruning ให้คะแนนต้นไม้ทั้งต้น (T) เป็น
$$ R_\alpha(T) = R(T) + \alpha |T|, $$ที่ (R(T)) คือ loss ของการฝึก, (|T|) คือจำนวนใบ และ (\alpha \ge 0) ใช้ลงโทษต้นไม้ใหญ่ ค่าที่สูงขึ้นทำให้ต้นไม้เรียบง่ายขึ้น
3. ทดลองด้วย Python #
โค้ดด้านล่างฝึก DecisionTreeRegressor หลายตัว และเปรียบเทียบ (R^2) ของ train/validation
เพื่อเห็นผลของ max_depth, min_samples_leaf, และ ccp_alpha
| |
ภาพด้านล่าง (ใช้รูปเดียวกับหน้า JP) แสดงผลของการปรับพารามิเตอร์หลัก:
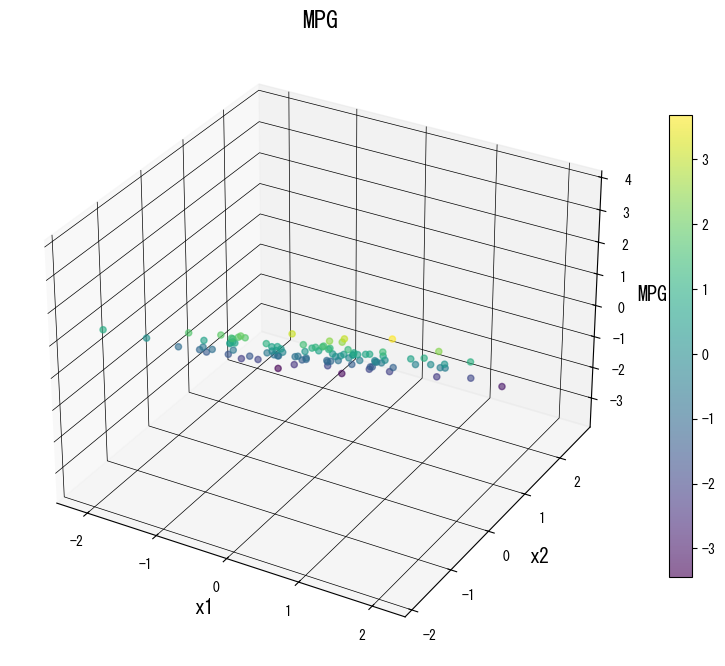
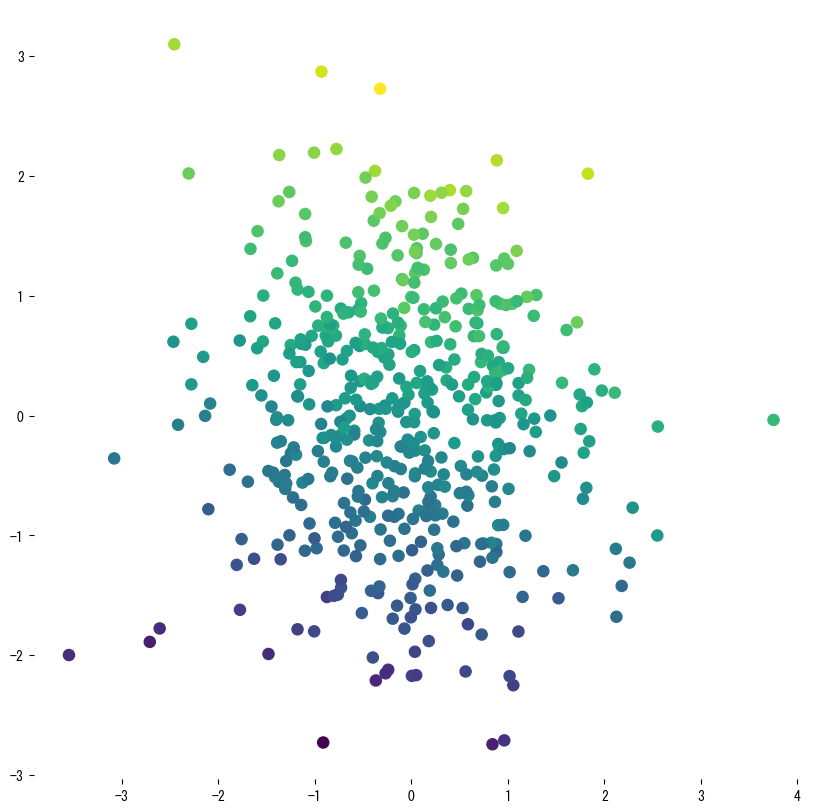
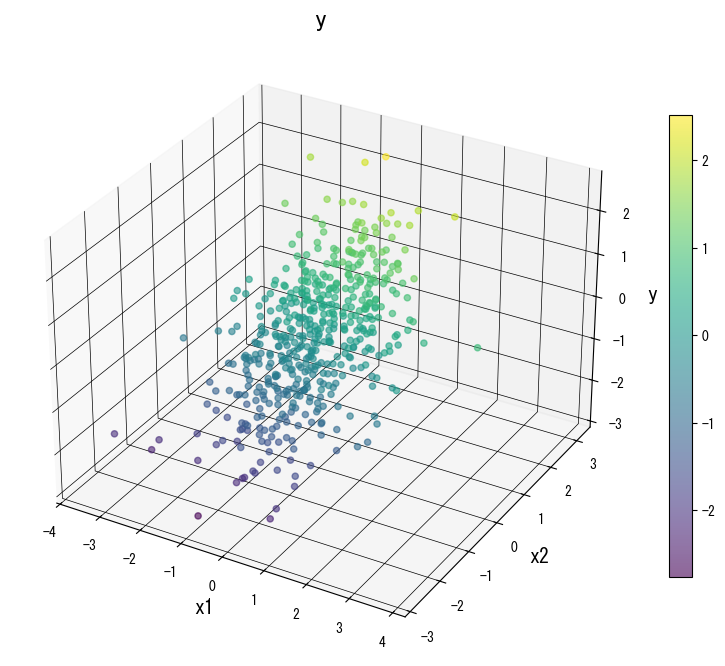
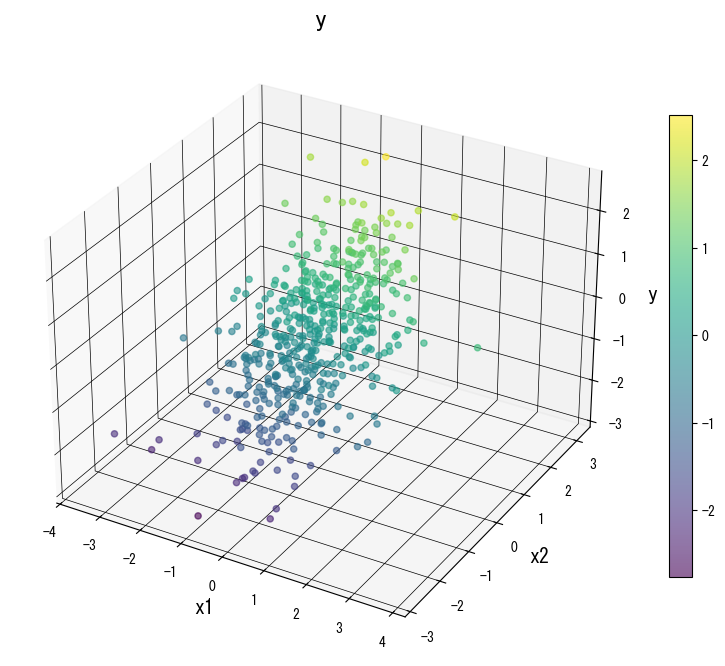
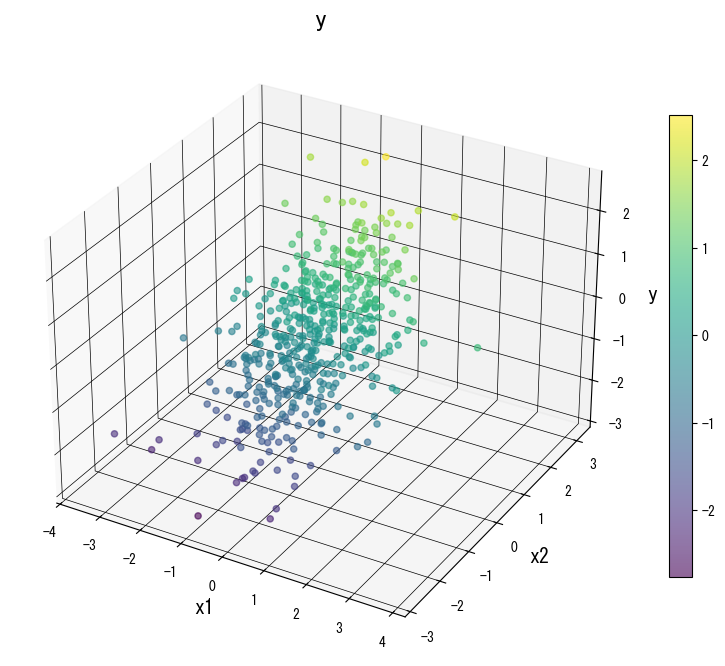
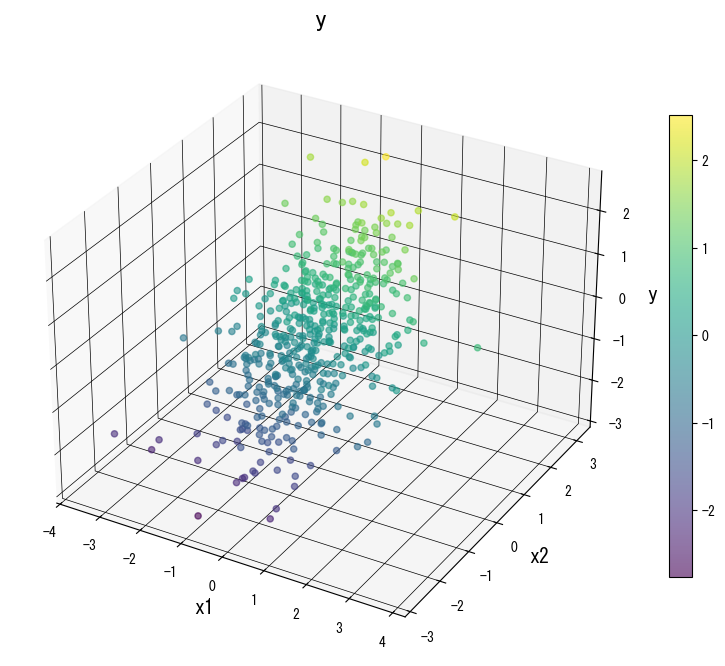
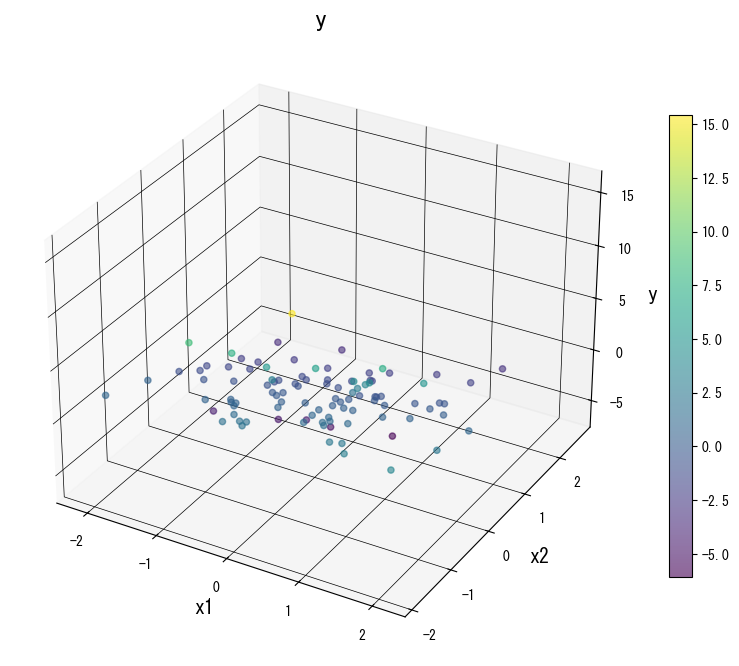
4. อ้างอิง #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- Breiman, L., & Friedman, J. H. (1991). Cost-Complexity Pruning. In Classification and Regression Trees. Chapman & Hall.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html