5.15.1
階層的時系列
まとめ
- 複数の時系列が階層構造(全社→事業部→製品など)を持つケースを理解する。
- 階層間で整合性のある予測を行うためのボトムアップ・トップダウン・最適調整の3つのアプローチを学ぶ。
- 商業動態統計の実データを例に、階層構造の具体的なイメージをつかむ。
- ARIMA モデル の概念を先に学ぶと理解がスムーズです
階層的時系列とは #
時系列データが複数あるとき、そのデータが階層的な構造を持つことがあります。
例:地域・カテゴリごとの販売データ #
経済産業省のサイトでは『商業動態統計』が定期的に公開されています。 これは、日本の商業を営む企業の販売活動の動向をチェックすることを目的として集められているデータです。たとえば、2022年1月の付表3 百貨店・スーパー販売 都道府県別、商品別販売額等には以下のようなデータが含まれています。
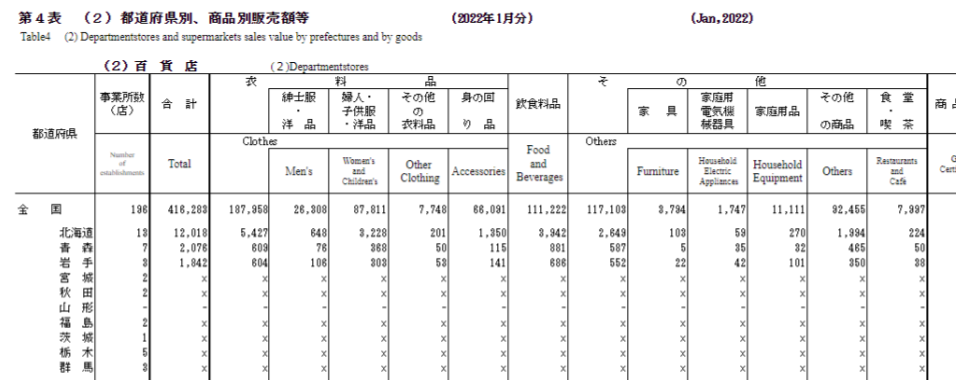
このデータには以下のような階層構造が含まれています。
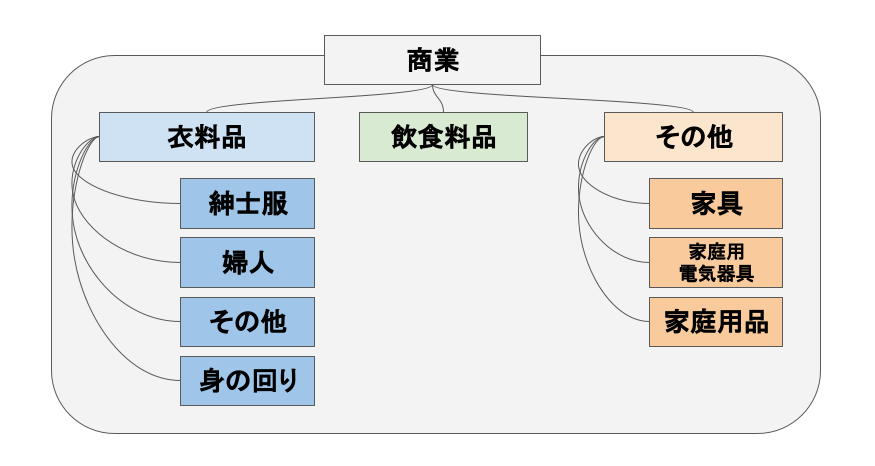
階層構造の具体例 #
企業の売上データを例にすると、次のような階層が考えられます。
全社売上
├── 事業部A
│ ├── 製品A-1
│ └── 製品A-2
└── 事業部B
├── 製品B-1
└── 製品B-2
このとき、各レベルの時系列には次の整合性制約があります。
- 全社売上 = 事業部Aの売上 + 事業部Bの売上
- 事業部Aの売上 = 製品A-1の売上 + 製品A-2の売上
各レベルで個別に予測すると、この合計の整合性が崩れることがあります。
予測の調整手法 #
階層的時系列の予測には、整合性を保つために3つの代表的なアプローチがあります。
ボトムアップ(Bottom-Up) #
もっとも細かいレベル(製品単位など)で個別に予測し、上位レベルは合算して求めます。
- 利点: 各製品の特性を反映しやすい
- 欠点: 末端データにノイズが多いと、集約しても精度が出にくい
トップダウン(Top-Down) #
全社レベルで予測し、過去の構成比率で下位レベルに配分します。
- 利点: 上位レベルの系列は安定していることが多く、予測精度が出やすい
- 欠点: 構成比率が変動する場合(新製品の投入など)に対応しにくい
最適調整(Optimal Reconciliation) #
全レベルで独立に予測し、最小分散基準などで整合性を満たすように事後調整します。
- 利点: 各レベルの情報を最大限に活用できる
- 欠点: 共分散行列の推定が必要で、実装がやや複雑
Pythonでの実装例 #
scikit-htsやhierarchicalforecastなどのライブラリで階層的予測を実装できます。
| |
| |
ボトムアップ予測の簡易例 #
| |
ボトムアップでは定義上、整合性が常に保たれます。トップダウンや独立予測では事後調整が必要です。
- ARIMA モデル — 階層各レベルで使える古典的予測モデル
- Prophetを使ってみる — Prophetで時系列を分解して予測
- STL 分解とフォーキャスト — STL分解後の残差にARIMAを適用して予測