2.2.1
Regresión logística
Resumen
- La regresión logística aplica una combinación lineal de las entradas a la función sigmoide para predecir la probabilidad de que la etiqueta sea 1.
- La salida está en \([0, 1]\), lo que permite fijar umbrales de decisión con flexibilidad y leer los coeficientes como contribuciones al logit.
- El entrenamiento minimiza la entropía cruzada (equivale a maximizar la verosimilitud); la regularización L1/L2 ayuda a evitar el sobreajuste.
- Con
LogisticRegressionde scikit-learn se cubren el preprocesamiento, el ajuste y la visualización de la frontera de decisión en pocas líneas.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
La probabilidad de la clase 1 dada \(\mathbf{x}\) es
$$ P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{w}^\top \mathbf{x} + b) = \frac{1}{1 + \exp\left(-(\mathbf{w}^\top \mathbf{x} + b)\right)}. $$El aprendizaje maximiza la log-verosimilitud
$$ \ell(\mathbf{w}, b) = \sum_{i=1}^{n} \Bigl[ y_i \log p_i + (1 - y_i) \log (1 - p_i) \Bigr], \quad p_i = \sigma(\mathbf{w}^\top \mathbf{x}_i + b), $$o, de forma equivalente, minimiza la entropía cruzada negativa. Agregar regularización L2 evita coeficientes inestables, mientras que L1 puede anular características irrelevantes.
Experimentos con Python #
El siguiente ejemplo ajusta la regresión logística a un conjunto sintético bidimensional y visualiza la frontera resultante. Gracias a scikit-learn, entrenar y trazar la frontera requiere pocas líneas.
| |
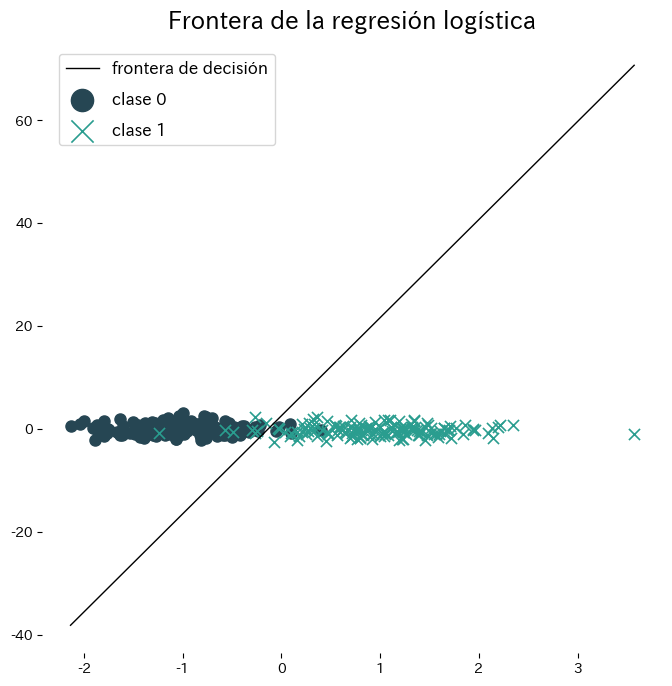
Referencias #
- Agresti, A. (2015). Foundations of Linear and Generalized Linear Models. Wiley.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.